Some months ago during the weekly inspection among the environments I’m keeping alive for my work projects, I’ve noticed there’s an increased number of warnings in AWS Elastic Beanstalk events dashboards for almost each application I took a look at. After a quick investigation there was an incontestable cause of this behavior, and as it turned out, it wasn’t that easy to solve the problem and clean the dashboard for the future.
All those events reporting false positives on health of each application make the confusion between the real state of the app and the state these events were reporting. And when it comes to the confusion, there’s no place for this in the current rapidly growing cloud approach where all the services we try to maintain which report lines of states and produce hundreds of lines of logs each minute or hour. If you can’t trust the health check, then how would you even know in what shape your application is at the moment? So we had to solve this issue as fast as possible and AWS WAF came into play and helped us with this quite significantly.
The problem
You might have experienced the same issue I had and there’s a big chance you don’t even know about it. According to my observation, each environment you create within the AWS Elastic Beanstalk service is most likely affected by this. There’s just no proper tool to use out of the box to find it out easily but it is so annoying that it happens for each autoscaled EB environment we created so far. If you take a closer look at the screenshot below, you’ll notice there’s a consistent change of the state between Ok and Warning.
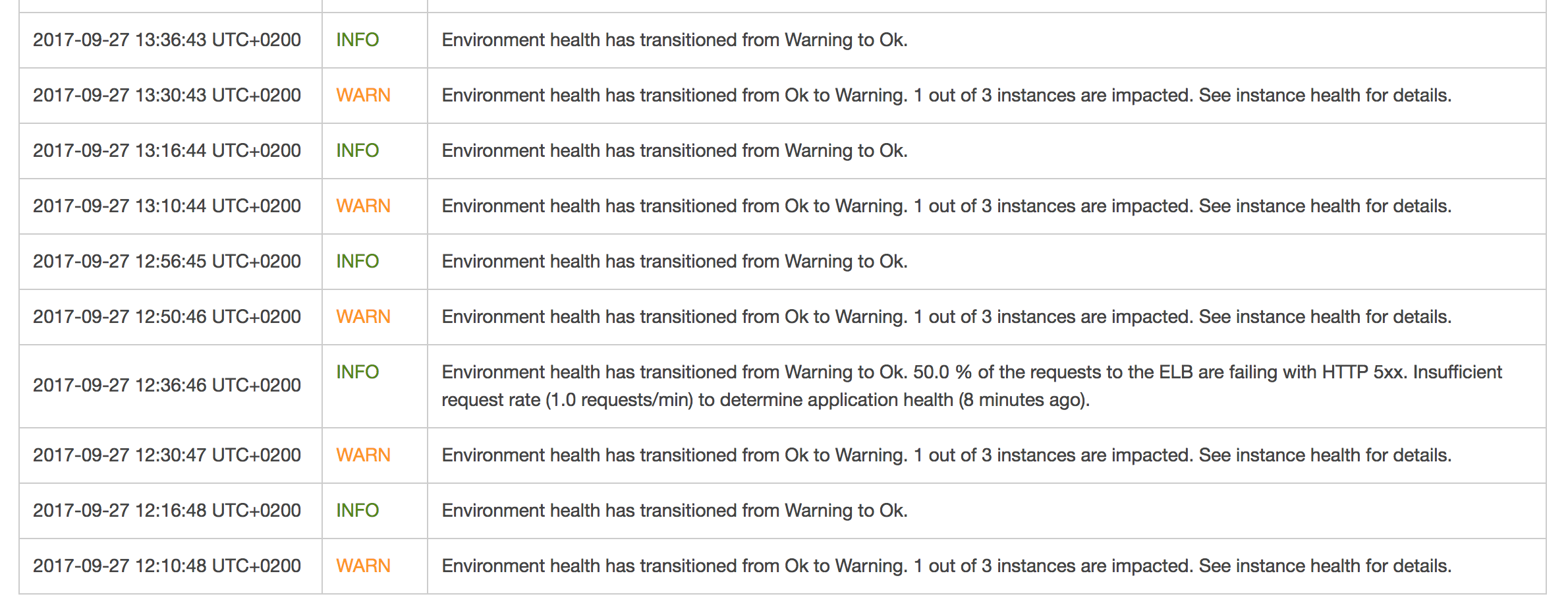
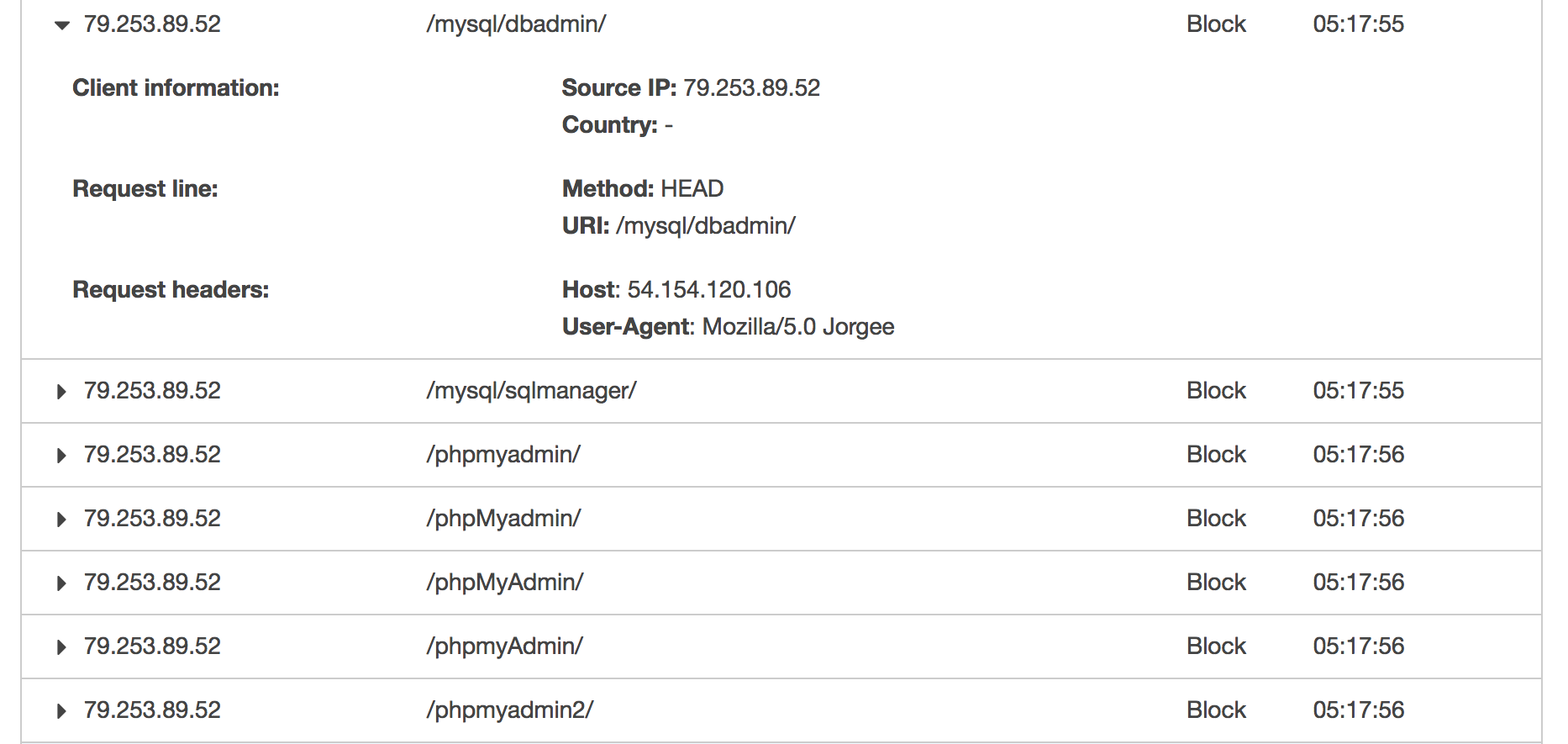
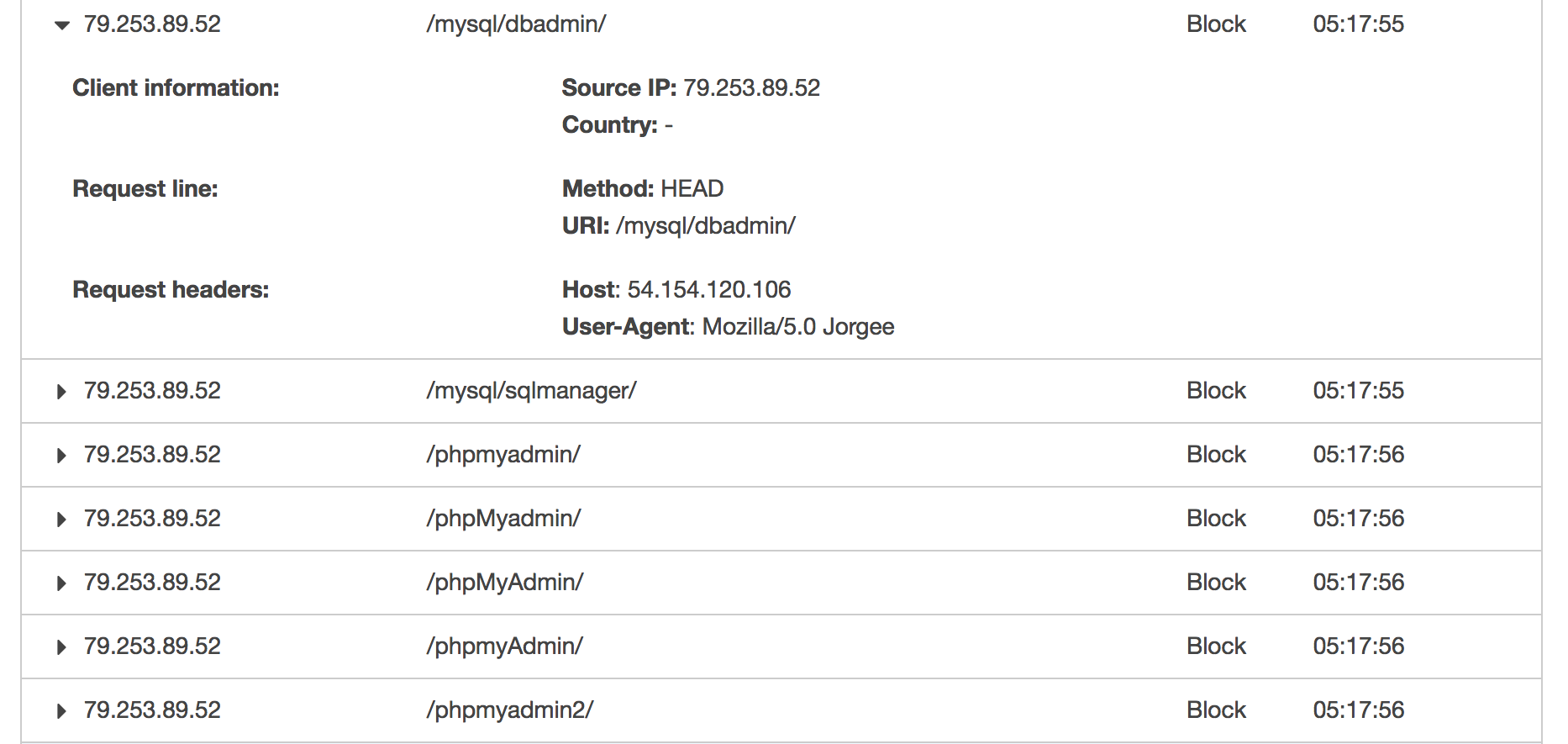
What’s more, one of the events reports an increased number of requests failing with 5xx status codes on Elastic Load Balancer level. That is definitely the worst case scenario you would ever encounter in your environment. Any 500-based status code indicates a problem you have not handled properly within your application. So you start looking for a cause, visiting your Sentry for errors, Datadog for alerts and requests charts, digging into the logs, running your investigation and… there’s nothing. The very first thing that comes up to your mind is that you’re doing something wrong with application monitoring or logging. Nothing more far away from the truth. Everything is fine and the sudden change of EB environment health (and all those 5xx statuses) comes from your Elastic Load Balancer and some bots doing a trivial scanning for paths. If you enabled the S3 logs for ELB, then you should investigate the files with the dates you see in your dashboard. And what do these bots do?
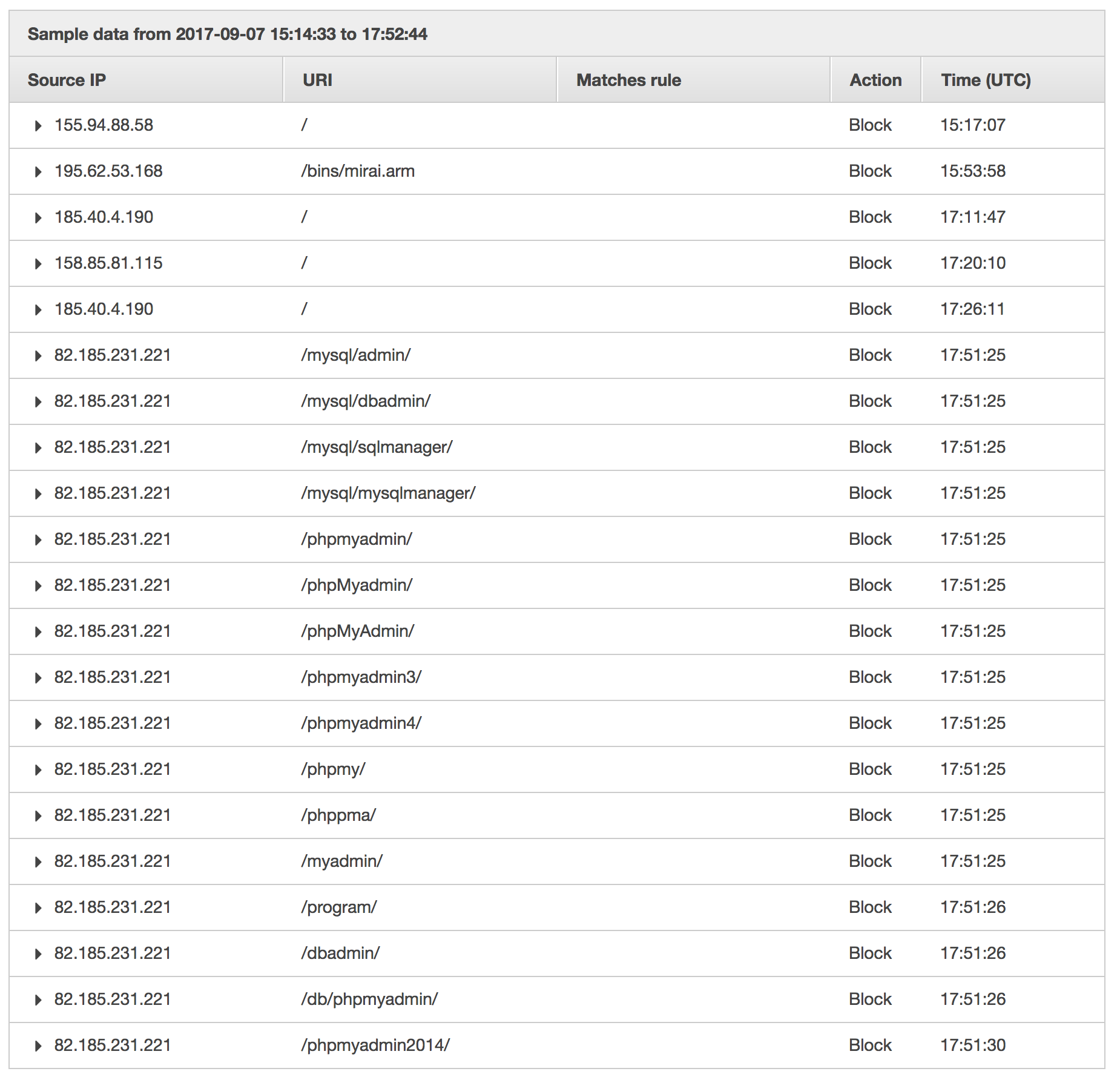
Not only do they try to find any path that may be used as vulnerability, but also overwhelm your application with a significant amount of requests at a time. The most annoying one, known as Jorgee, will likely be scanning your new EB environment every time you create a new one. In line with my observations, it performs scanning within the first minutes of your environment’s existence and keeps on scanning every couple of hours at least. The screenshot below presents some constant parts of each scan. What Jorgee bot does is taking your AWS ELB IP address (which is not advised to be used as it changes infrequently and is not constant) and performs scanning on it with User-Agent: Mozilla/5.0 Jorgee. By using the IP address of AWS ELB and not the DNS name, it causes 5xx status codes to occur. And that is being seen by EB environment as the 5xxs in your application. It should be definitely limited on AWS environment level as it’s so easy to generate false positives in error dashboard on EB right now. But it’s not, so we need to solve it somehow.
The solution
As I mentioned in the introduction, AWS WAF comes into play here. I need to confess first, that I didn’t know anything about this service until I got stuck on a case described here. I’ve barely known WAF so AWS Support showed me the way to go. And I took the advantage of it and now it’s the very first perimeter of any application we take seriously. That’s the filter any incoming request must pass through until it reaches the application itself. And with this fact comes the possibility. As WAF service works on the same level as Elastic Load Balancer, it gives an opportunity to filter any unnecessary thing out. Such a funnel may be compared to a bridge before the castle, that goes up when the visitor is not welcome, so it falls into the moat, while other guests may reach the castle. It’s up to us what kind of default policy we take. I took the approach of denying everything by default and then created some allowance rules. It’s easier for me to say what’s ok, than limit anything that’s not.
The solution I’m going to describe here will not make my application bot-proof in any sense, but it will eliminate those changes of environment’s health along with 5xx codes in my dashboard, so I will be able to determine the state of my application just by taking a look at the health reports. As Jorgee bot (and many others) uses IP of Elastic Load Balancer to perform scanning, what we need to do is to eliminate any traffic that is not happening within a desired domain of our application. This approach will filter out any of the bots I’ve met in various environments on AWS EB.
Let’s start with creating a Condition as a String match. It will verify each request against Host header match to any domain name we need.
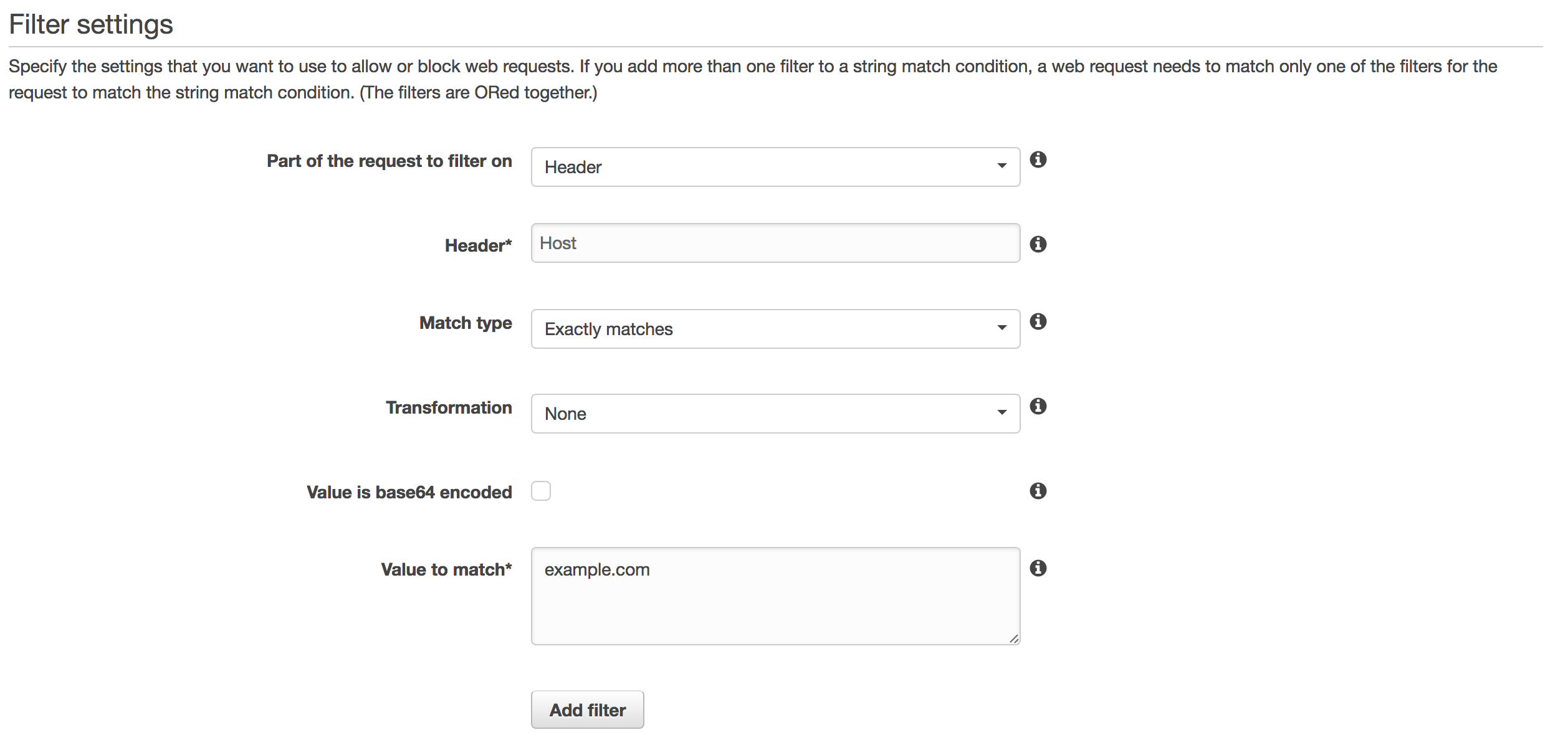
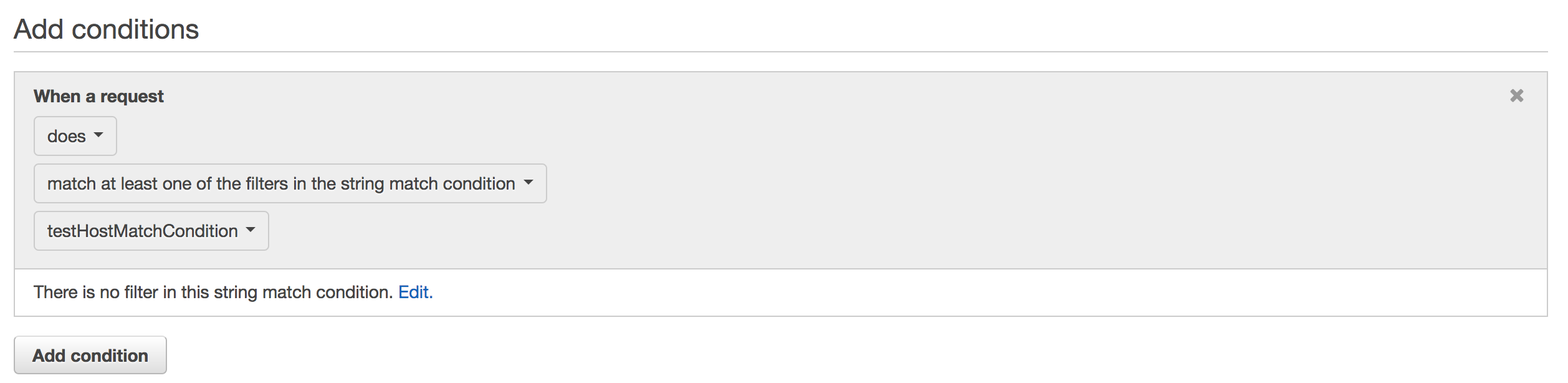
Then we need to create a Rule based on the condition created before. We choose match at least one of the filters in string match condition, and then we select our new condition from the previous step.
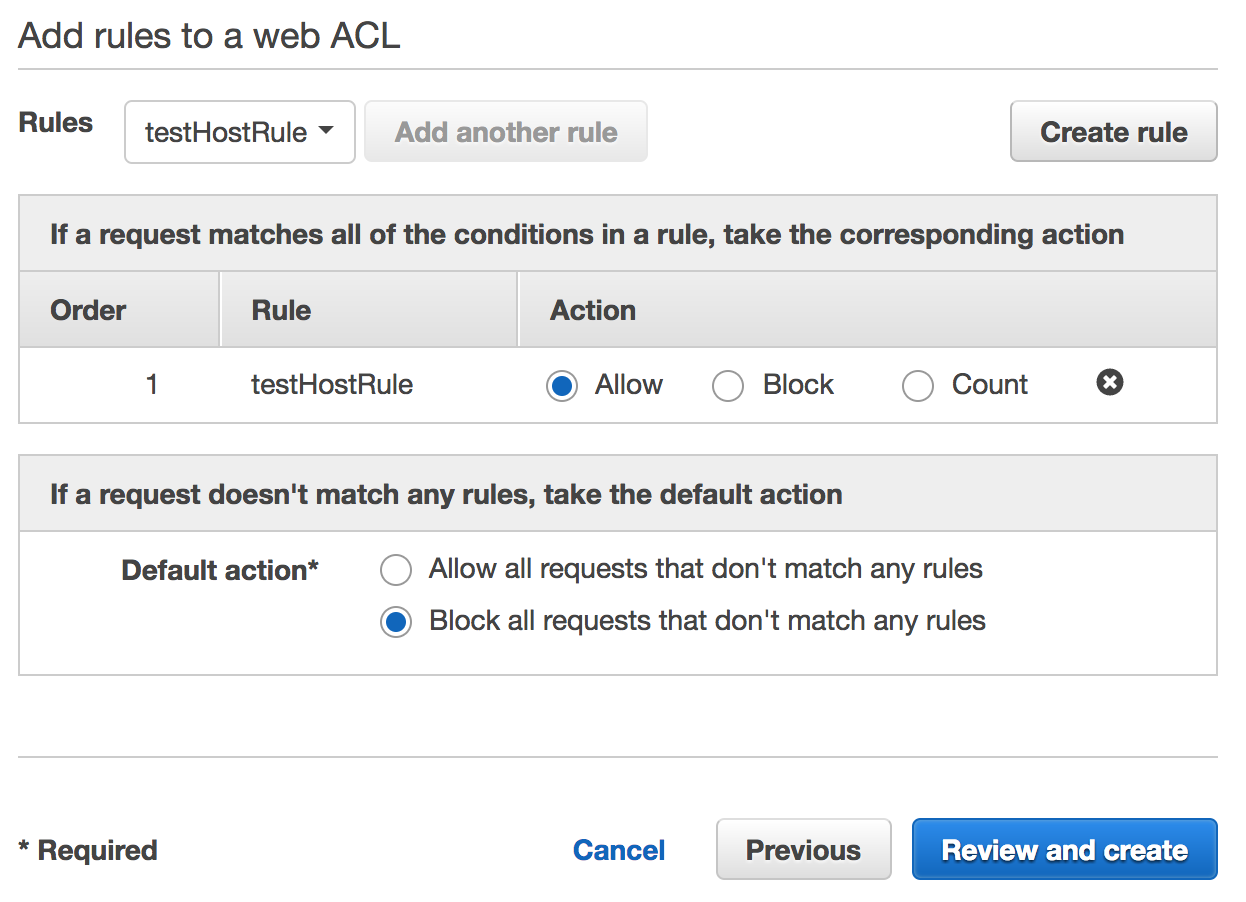
The last step will take place in the Web ACLs tab. We need to create a new Web ACL, give it a name and pick an Elastic Load Balancer name it will be connected to. Then with Next clicked two times, as we can omit the next tab because we’ve already created all the conditions and rules we need, we reach the most important part of the WAF here. We select a Rule from the dropdown and click Add another rule. Our rule will be added to the Rules list and now we can select Action being taken for the rule as well as default action when none of the rules will be met. I choose to block anything that’s not passing the conditions and allow a traffic for Host header matched requests.
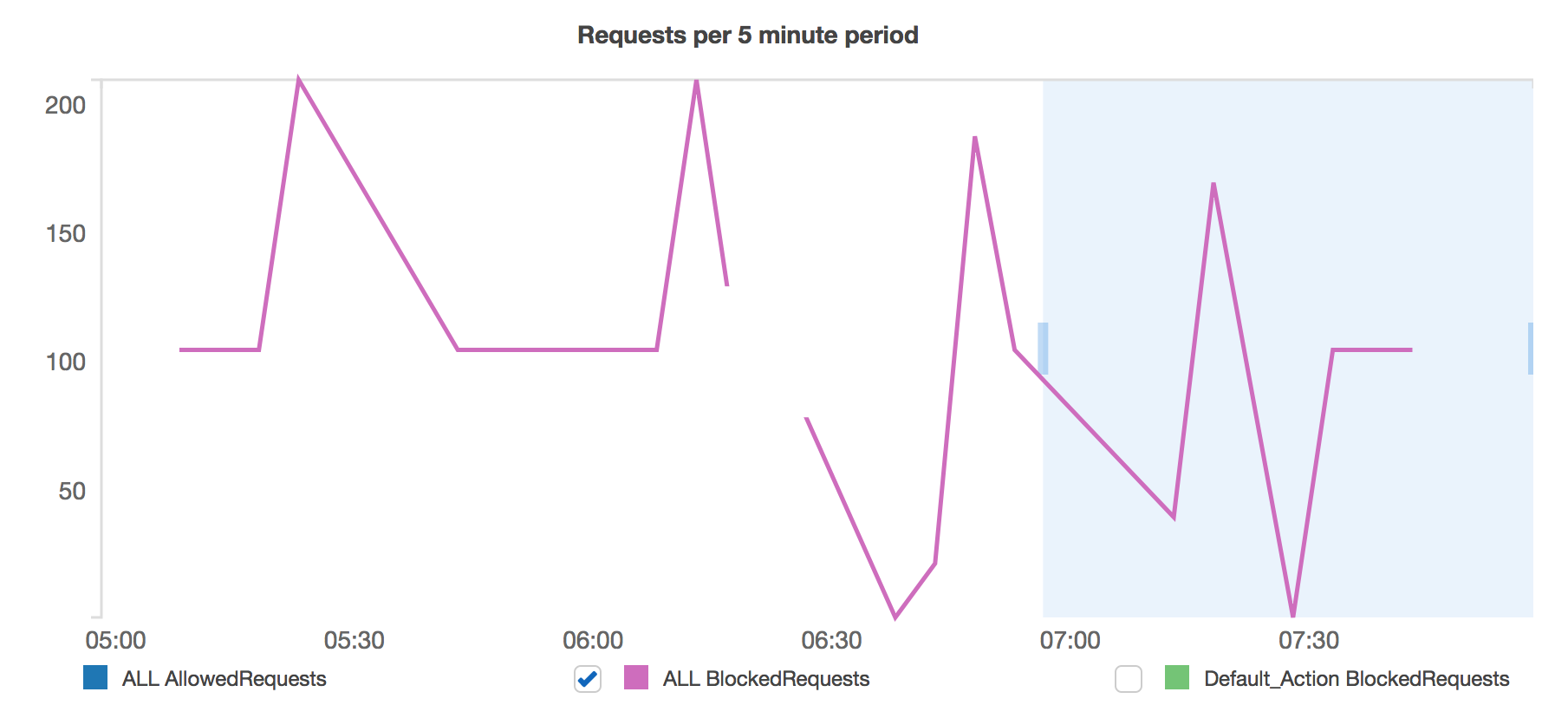
And we’re done! From this point on, requests will be filtered against these rules and will get in response either 403 status when blocked or the desired request URLI will be passed through when accepted. AWS WAF creates Cloudwatch metrics for the created objects so we’re able to follow the traffic as it goes on. As may be seen below, there’s a lot of incoming requests, but from now on we’re able to monitor them somehow. Just notice how many requests are being blocked. All of these come from bots.
The summary
Being aware of anything that happens on your environment helps a lot obviously. Obfuscated, blacked out logs will not be helpful when it comes to the worst things. By filtering out any unnecessary traffic we’re making our logs clear, healthchecks valid and comprehensive, and us happy and well prepared. And while I’m aware of the fact that this solution is trivial and won’t make the application immune to anything indeed, it makes the logs what they are supposed to be - useful. And with that we can be at least one step closer to the proper monitoring of AWS Elastic Beanstalk application.